MARS: Episode-Scoped GPU Retrieval for Real-Time Embodied AI
A child’s ball rolls into the road from behind a parked van. The vehicle’s camera sees only the ball. But 600 ms earlier, the microphones captured children’s voices from that same direction — a memory that, if retrievable now, raises the prior that a child may follow the ball into the street.
The useful memory is 600 ms old, from a different modality than the query, and low in cosine similarity compared to countless irrelevant alternatives. No ranking by similarity alone can surface it.
The interesting observation is that an embodied perception stack already knows more than “find me the nearest vector” at query time. It carries an active track id, a dialogue session, an AR room, or a robot sub-task — the right answer almost always lives inside that episode. The whole content of MARS — Memory for Autonomous Real-time Systems — is what happens when you take that observation seriously and push it into a GPU kernel.
Read the full paper (PDF, 1.97 MB)
MARS treats episode handles as a kernel parameter. When the application can supply the active track / session / room / sub-task id, retrieval becomes a 197 µs operation at N=1M — 33× faster than the only GPU baseline that retains perfect cross-modal recall on this contract, and the only configuration that fits inside the 1 ms autonomous-vehicle deadline at that corpus size. The rest of this post is what falls out of taking that one design move seriously: how the kernel pipeline changes, how the multimodal graph is structured, what happens to the recall axis at scale, and what the contract is not good for.
What existing libraries do well — and where they stop
FAISS GPU and cuVS CAGRA are excellent at finding the K most similar vectors in a static corpus. The contract they expose is: over the entire indexed corpus, return the K vectors with highest cosine similarity. For document retrieval, recommendation, image search — that’s the right contract.
Embodied workloads typically know more than that at query time. The question isn’t “find me the closest vector globally” — it’s “find any recent sensor evidence, across any modality, relevant to this current track.” Encoding that knowledge as host-side post-filtering on the output of a global ANN sweep wastes GPU work and, as the head-to-head benchmark below shows, breaks recall at scale on tiny multimodal clusters.
A first concrete instance of the same idea is temporal decay. Recency is a first-class ranking signal in a sensor stack — but cosine ANN libraries don’t fold it into the kernel:
| System | Temporal Precision@10 | p99 latency |
|---|---|---|
| FAISS Flat (cosine only) | 0.218 | 0.13 ms |
| FAISS + post-hoc temporal filter | 0.910 | 0.25 ms |
| MARS (native temporal decay) | 0.910 | 0.26 ms |
| Ring buffer + cuBLAS SGEMV (N=2,400) | — | 0.12 ms |
MARS matches FAISS+filter at identical TP@10 (0.910) and a comparable per-query latency (0.26 ms vs 0.25 ms p99). The 0.01 ms gap is within run-to-run noise on a non-locked-clock A100, so the contribution here is API consolidation — the temporal filter becomes a kernel parameter rather than a second pipeline stage — rather than a raw speedup. A raw cuBLAS-only ring buffer is 3.2× faster (0.12 ms at N=2,400) but provides no temporal decay, no cross-modal retrieval, and no streaming insertion.
That’s the warm-up; the larger contribution is what happens when an episode handle is also pushed into the kernel.
Head-to-head against modern GPU ANN libraries
The contract is the embodied multimodal one: the query is an IMAGE node and we measure hit@15 of the same-episode TEXT and AUDIO neighbors (kids-ball corpus, paired RNG seed=2026, A100 SXM4 40 GB).
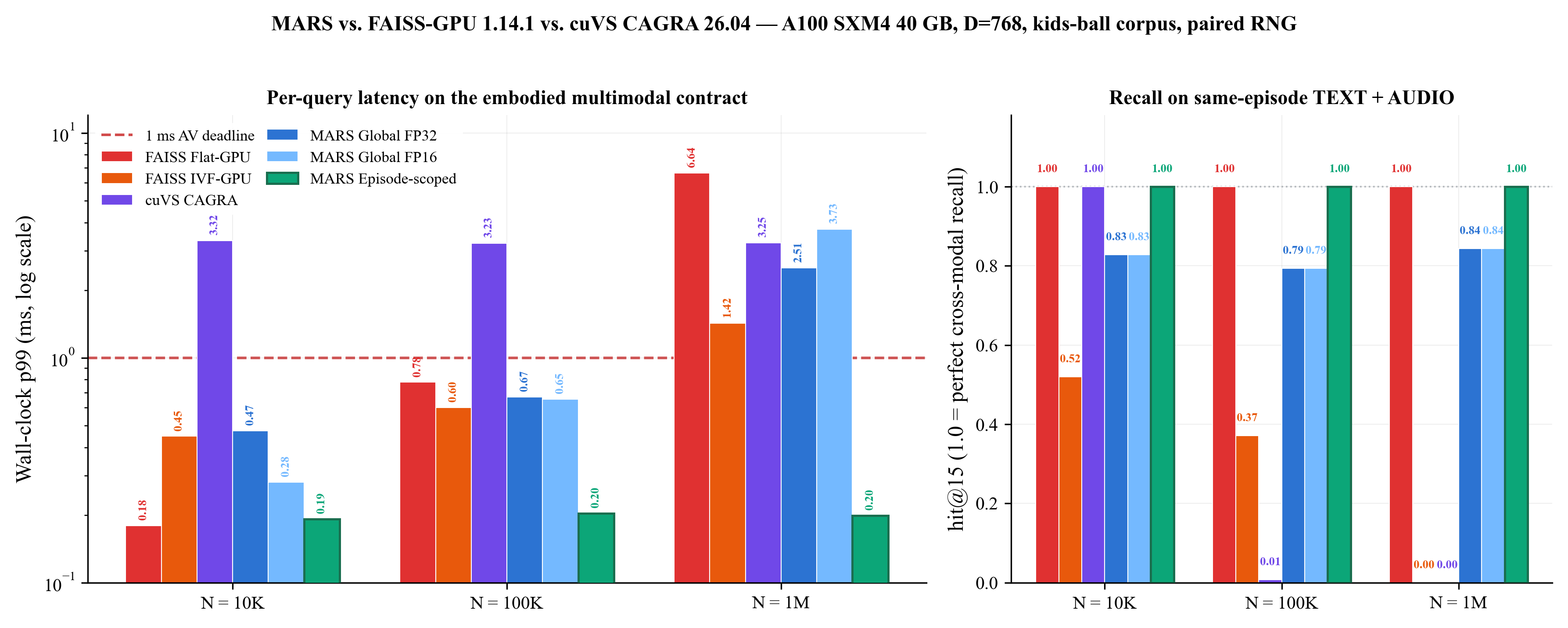 Figure 7 from the paper: head-to-head wall-clock p99 (left, log scale) and
Figure 7 from the paper: head-to-head wall-clock p99 (left, log scale) and hit@15 (right, linear) on the kids-ball multimodal contract. MARS Episode-scoped (rightmost green bar in each group) is the only system that is simultaneously below the 1 ms AV deadline and at perfect recall across all three corpus sizes.
| System | N=10K p99 / hit@15 | N=100K p99 / hit@15 | N=1M p99 / hit@15 |
|---|---|---|---|
| FAISS Flat-GPU (exhaustive) | 0.18 ms / 1.00 | 0.78 ms / 1.00 | 6.64 ms / 1.00 |
| FAISS IVF-GPU (nprobe=64) | 0.45 ms / 0.52 | 0.60 ms / 0.37 | 1.42 ms / 0.00 |
| cuVS CAGRA (graph_degree=64) | 3.32 ms / 1.00 | 3.23 ms / 0.01 | 3.25 ms / 0.00 |
| MARS Global (FP32 cuBLAS) | 0.47 ms / 0.83 | 0.67 ms / 0.79 | 2.51 ms / 0.84 |
| MARS Global (FP16 fused) | 0.28 ms / 0.83 | 0.66 ms / 0.79 | 3.73 ms / 0.84 |
| MARS Episode-scoped | 0.19 ms / 1.00 | 0.20 ms / 1.00 | 0.20 ms / 1.00 |
Two findings drove the design:
- MARS Episode-scoped is Pareto-optimal on the latency–recall frontier at every N: 33× faster than FAISS Flat at 1M and 16× faster than CAGRA, both at perfect recall on this metric. (“Pareto-optimal” here means: no measured baseline is simultaneously faster and better-recall on this contract; I make no claim about other latency–recall metrics or about other corpora.) When the application can supply an episode handle, restricting the kernel to episode members converts a
Θ(N · D)cosine sweep into aΘ(|episode| · D)kernel that the A100 finishes in 197 µs independent of N. - Cosine ANN baselines collapse on this metric at scale. The kids-ball corpus has tiny clusters (10 nodes per episode, 100 K episodes at 1M), so per-episode TEXT/AUDIO neighbors are buried among ~999 990 distractors. CAGRA’s graph traversal (even at
search_k=512) and IVF cells (anynprobe) miss them. MARS keeps episode membership in the graph topology and recovers them in O(member_count). FAISS Flat alone keeps recall at N=10⁶ because it is exhaustive — at 6.64 ms p99 it sits 6.6× past the 1 ms AV deadline.
Synthetic-corpus disclaimer. The kids-ball benchmark uses Gaussian-perturbed cluster centroids in 768-D with a known, dense small-cluster structure. Real-encoder embeddings (CLIP, CLAP, E5) have different distance distributions and broader clusters; the exact crossover N at which cosine ANN loses recall on real data may shift. The qualitative point — that exhaustive cosine + episode CSR is the right primitive when episodes are known and small — should generalise; the absolute hit@15 numbers should not be quoted without re-measurement on the target encoder. A real-encoder validation run is the first item in §10.1 of the paper.
What would be a fairer FAISS baseline. A FAISS-Flat-GPU sweep with
IDSelectorBatchorIDSelectorRangeset to the episode member ids would do roughly the same work as MARS Episode-scoped and is the next baseline to add. It is queued in §10.1 as the first item of Evaluation Hardening. I expect it to be the same order of magnitude as MARS-Episode — the win MARS keeps would then be that the episode CSR is built into the same data structure as the cross-modal NSN, not that the cosine kernel is somehow faster.
Episode-scoped retrieval is near-flat
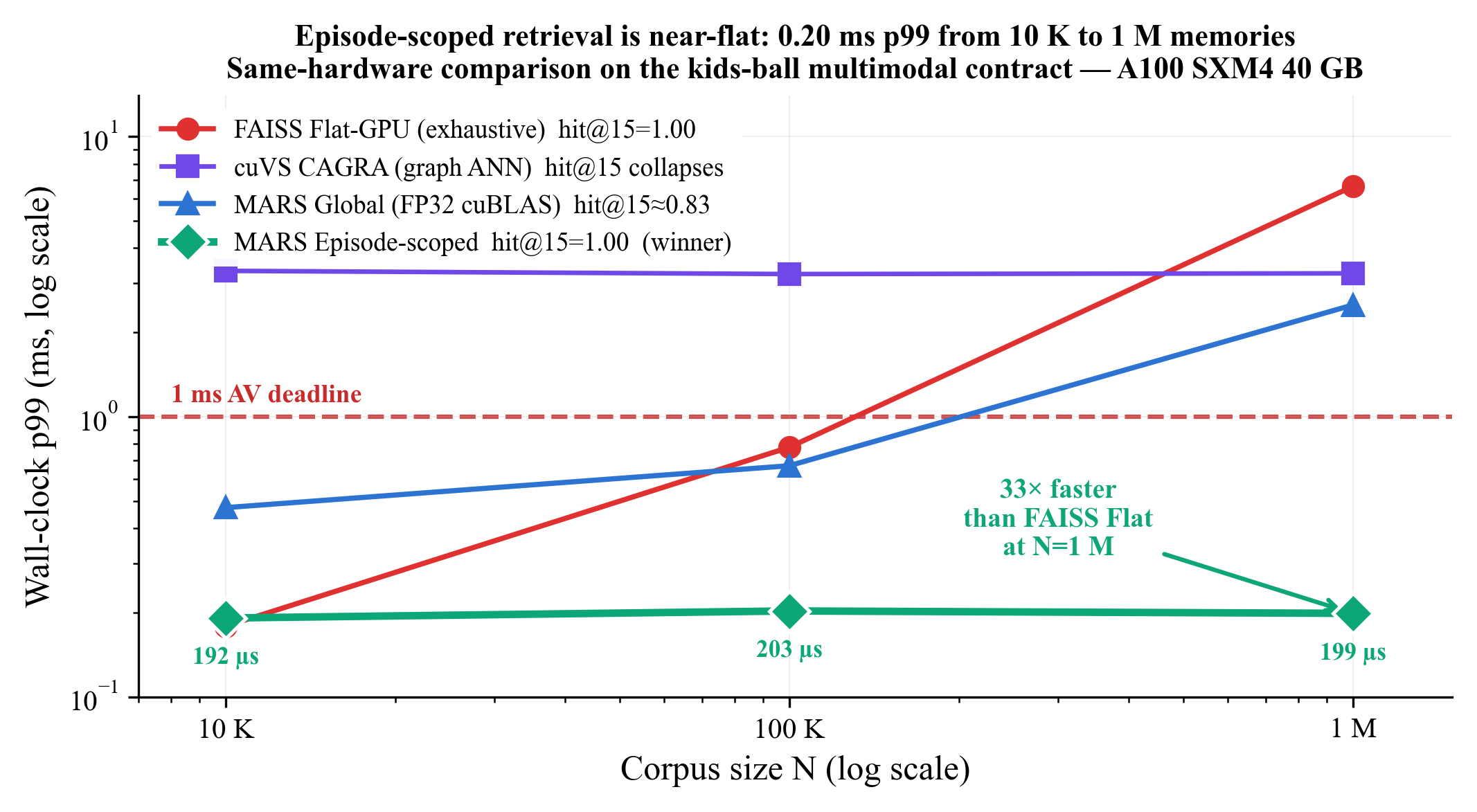 Figure 6 from the paper: episode-scoped MARS (green diamonds) is near-flat at ~200 µs across three decades of N while keeping perfect cross-modal recall; the only baseline that also achieves
Figure 6 from the paper: episode-scoped MARS (green diamonds) is near-flat at ~200 µs across three decades of N while keeping perfect cross-modal recall; the only baseline that also achieves hit@15=1.00 (FAISS Flat) crosses the 1 ms AV deadline already at N=10^5 and is 33× slower at N=1M.
The episode-scoped curve grows by only ~19 % as N goes from 10⁴ to 10⁶, because the GPU work is bounded by the episode size (~10 members), not by N. At N=1M the path delivers 197 µs p99 wall-clock — below every per-frame deadline including the 1 ms AV budget — while returning a perfect-recall multimodal answer.
When does the contract apply? Episode scope is correct only when the right episode is known before the query. It is the natural contract for AV per-track re-identification (track id is the episode), voice-agent turn taking (session id is the episode), AR/VR per-room recall (room id is the episode), and embodied task loops (current sub-task id is the episode). It is not correct for open-ended global semantic search — but that workload has the wider deadline (10–100 ms) where the global path or a cosine ANN baseline already fits.
The paper’s Episode-Scope Crossover proposition (§6.3) makes this concrete: episode-scoped beats global on a bandwidth-bound model when |episode| / N + ε_overhead < 1, which on the kids-ball corpus is satisfied for any N ≥ ~1K. It also derives an upper bound on the recall advantage as a function of episode density vs distractor density — useful for predicting whether the contract is worth wiring into an application before measuring.
Two contracts, one GPU-resident substrate
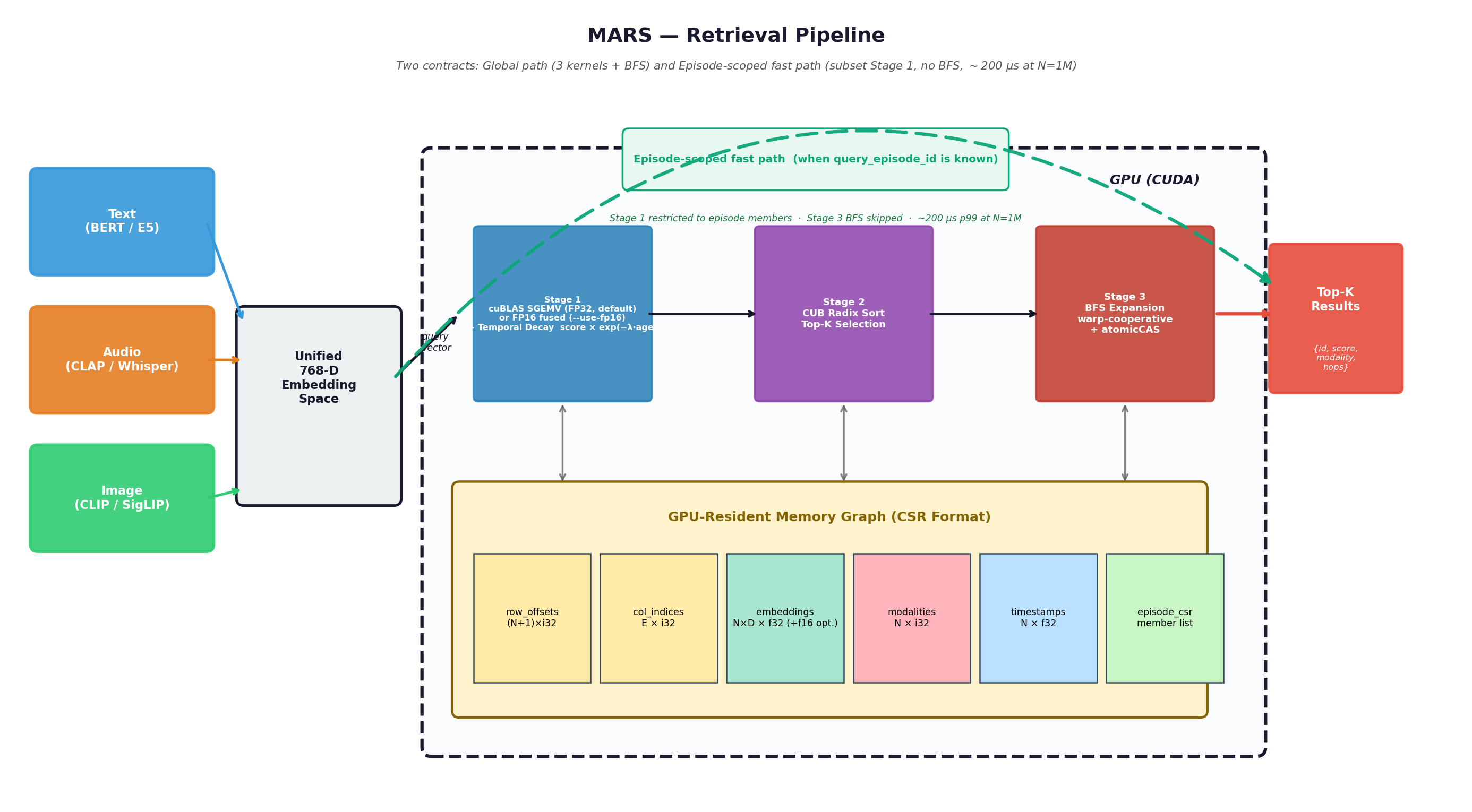 Figure 1 from the paper: MARS retrieval pipeline. Sensor encoders (left) feed a shared 768-D embedding space; four GPU kernels orchestrate retrieval over a CSR-format memory graph resident in device memory. The green dashed arc is the episode-scoped fast path.
Figure 1 from the paper: MARS retrieval pipeline. Sensor encoders (left) feed a shared 768-D embedding space; four GPU kernels orchestrate retrieval over a CSR-format memory graph resident in device memory. The green dashed arc is the episode-scoped fast path.
MARS stores text, audio, image, and sensor embeddings in a shared 768-D space as nodes in a Neural Shortcut Network (NSN) with cross-modal bridges. Two contracts share the same GPU-resident data:
Global path (when no episode handle is available): four kernels, sub-millisecond at N ≤ 50K, zero per-query allocation.
- Stage 1 — Cosine + temporal decay. Default: cuBLAS
Sgemv(FP32) followed byscore × exp(-λ·age). Opt-in--use-fp16switches to the hand-fused FP16 cosine kernel — wins by 41 % at N=10K but loses by 49 % at N=1M. - Stage 2 — CUB radix sort top-K in O(N).
- Stage 3 — Warp-cooperative BFS through NSN bridges with
atomicCASrace-free neighbor claiming. Score propagation rule (Algorithm 1 in the paper):score[u] ← max(score[parent] · δ_prop, sim[u] · α_bfs)with defaultsδ_prop = 0.85(per-hop attenuation) andα_bfs = 0.8(cap on raw similarity for purely-graph-discovered nodes). Temporal decay is not re-applied during BFS — it has already been folded intosim[u]at Stage 1.
Episode-scoped fast path (when query_episode_id is supplied): Stage 1 is restricted to the episode’s CSR member list and Stage 3 BFS is skipped entirely. The result is the green dashed arc in the diagram above and the near-flat scaling curve in the previous section.
When FP16 fused beats cuBLAS Sgemv (and when it doesn’t)
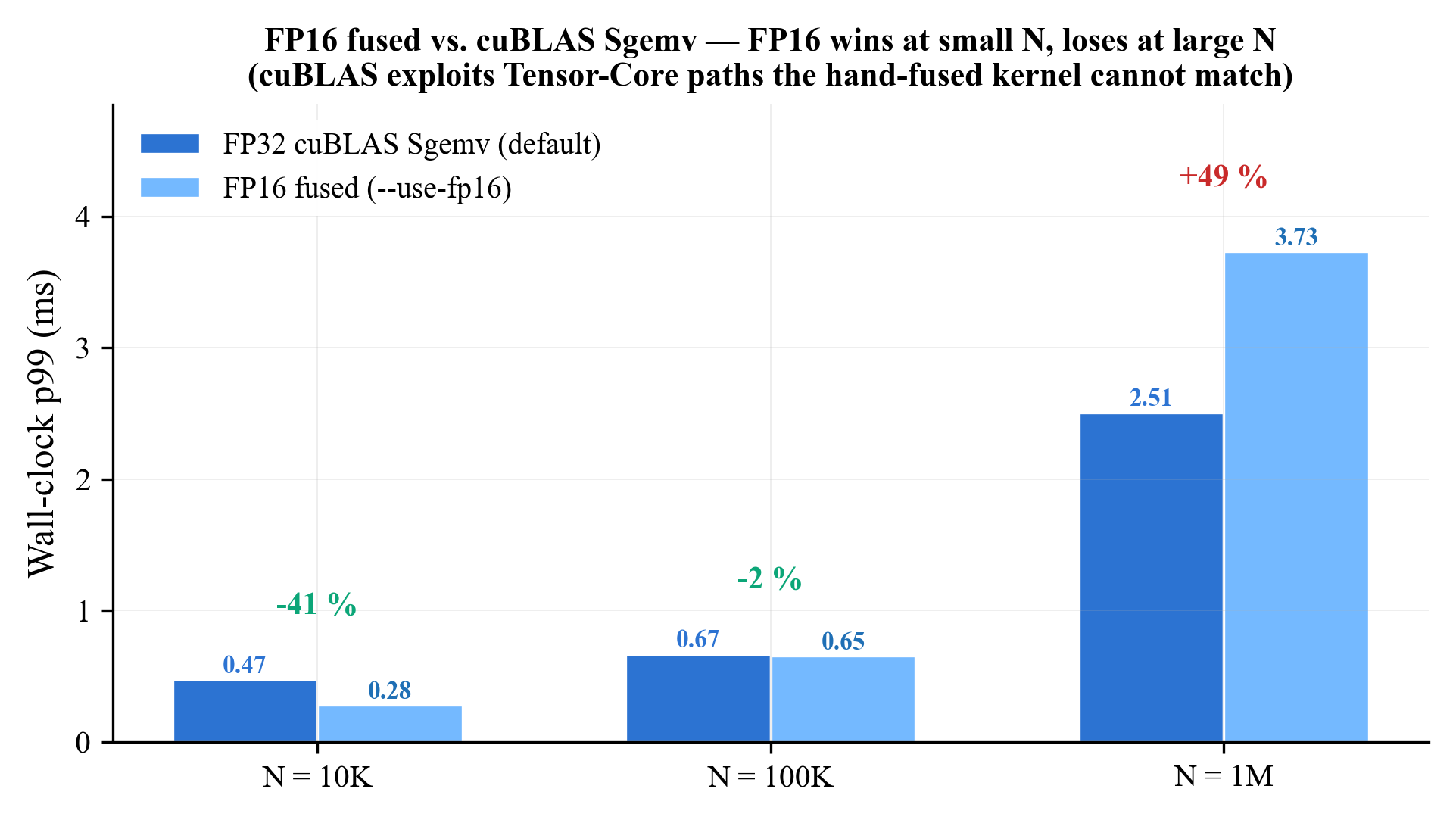 Figure 8 from the paper: the hand-fused FP16 cosine kernel wins at small N where the working set fits in L2, but cuBLAS
Figure 8 from the paper: the hand-fused FP16 cosine kernel wins at small N where the working set fits in L2, but cuBLAS Sgemv engages Tensor-Core paths that the fused kernel cannot match at large N. The default deployment uses cuBLAS; --use-fp16 is documented as a small-N opt-in.
The hand-fused FP16 cosine kernel is bandwidth-optimal at small N because the entire embedding tile fits in L2 and the dot product becomes memory-bound. cuBLAS Sgemv cannot beat that at N=10K. But once N exceeds the L2 working set, cuBLAS’s Tensor-Core paths and per-arch tile heuristics dominate — FP16 fused regresses by 49 % at N=1M.
This is one of the more honest findings of the paper: bring-your-own-kernel is not always faster than vendor BLAS, and the crossover point is hardware- and corpus-size dependent. The build defaults to cuBLAS; --use-fp16 is documented as a small-N opt-in.
Scaling and deadline compliance
Measured on A100 SXM4 40GB (D=768, K=10, cuBLAS+CUB):
| Corpus | Global path p99 | Episode-scoped p99 | Status |
|---|---|---|---|
| 1K | 0.31 ms | — | Sub-ms |
| 10K | 0.44 ms | 0.19 ms | Sub-ms |
| 50K | 0.56 ms | 0.17 ms | Sub-ms |
| 100K | 0.74 ms | 0.20 ms | Sub-ms |
| 1M | 2.67 ms | 0.20 ms | Real-time only via Episode-scoped |
| 10M | 22.3 ms | (mem-bound) | Batch |
| 13M | 29.1 ms | (mem-bound) | VRAM limit |
Five workloads pass empirical p99 deadlines on A100:
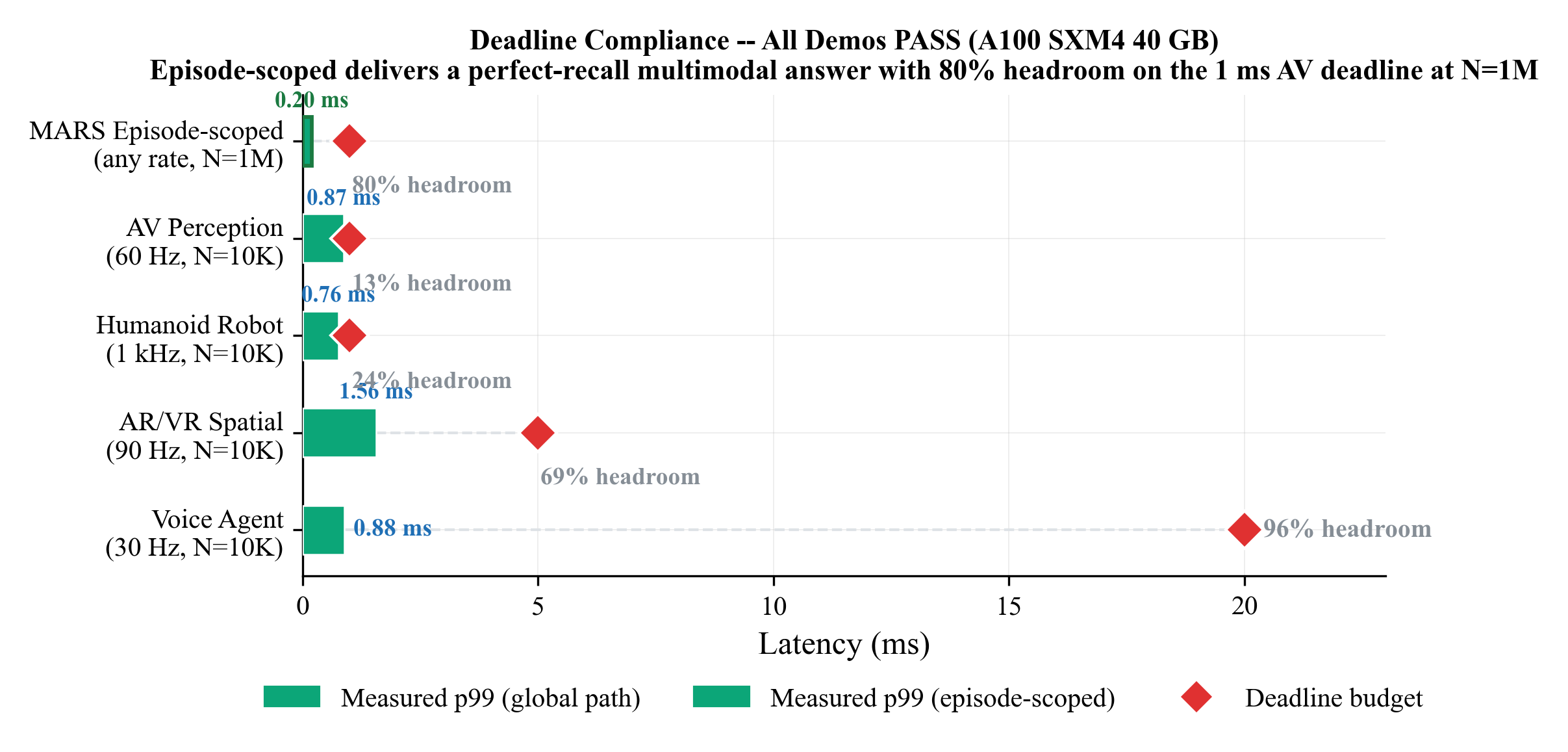 Figure 4 from the paper: deadline compliance for all four demonstrators on A100 SXM4 plus the episode-scoped path at N=1M. All pass; episode-scoped delivers a perfect-recall multimodal answer with 80% headroom on the 1 ms AV deadline at N=1M.
Figure 4 from the paper: deadline compliance for all four demonstrators on A100 SXM4 plus the episode-scoped path at N=1M. All pass; episode-scoped delivers a perfect-recall multimodal answer with 80% headroom on the 1 ms AV deadline at N=1M.
| Workload | Rate | Budget | Measured p99 | Headroom |
|---|---|---|---|---|
| AV perception (N=10K) | 60 Hz | 1 ms | 0.87 ms | 13 % |
| Humanoid robot (N=10K) | 1 kHz | 1 ms | 0.76 ms | 24 % |
| AR/VR spatial (N=10K) | 90 Hz | 5 ms | 1.56 ms | 69 % |
| Voice agent (N=10K) | 30 Hz | 20 ms | 0.88 ms | 96 % |
| MARS Episode-scoped (N=1M) | any | 1 ms | 0.20 ms | 80 % |
The last row is the one I’d flag for embodied roboticists: a perfect-recall multimodal answer at sensor rate against a million-memory corpus, with 80 % headroom on the AV deadline.
A statistical-honesty note
All the p99s above are over 128–256 paired probes on non-locked-clock vast.ai instances with shared multi-tenant hosts. At sub-millisecond scale, run-to-run jitter is on the order of ±10 % and the 12th-largest of 128 samples has wide confidence intervals. Concretely:
- The 0.26 ms vs 0.25 ms gap on the temporal-decay experiment is well within noise; quoting either as “winning” would be misleading.
- The flip in the FP16-vs-cuBLAS large-corpus table where RTX 5060 Ti looks faster than A100 SXM4 at N=500K but slower at N=1M is reported faithfully but should not be over-interpreted.
- The episode-scoped advantage at N=1M is large enough (13× over MARS-Global, 33× over FAISS-Flat) that no plausible jitter explains it away — this is the one number I’d defend even after locked-clock re-measurement.
The paper carries an explicit Measurement Methodology and Statistical Caveats subsection (§7.2) and an Evaluation Hardening track (§10.1) that lists the locked-clock re-runs, the real-encoder benchmark, the FAISS+IDSelector head-to-head, the standard temporal-IR metrics (TS-Recall@10, time-NDCG@10), and per-stage Nsight Compute breakdowns. Cost ~$15, time ~2 days; queued for the next iteration.
The Neural Shortcut Network
What makes MARS more than “cuBLAS with a timestamp column” is the graph structure. Memories are nodes in a CSR-format graph built in five phases:
- Ring lattice (k=6 local neighbors)
- Hierarchical skip connections (powers of 2)
- Hub supernodes at √N intervals
- Small-world rewiring (Watts–Strogatz, p=0.15)
- Cross-modal bridges — every node gets one edge to each other modality
Phase 5 is critical: a query starting with an audio embedding reaches visual and text memories through graph traversal, without separate per-modality indices. The warp-cooperative BFS kernel explores these bridges in <0.04 ms.
The construction is deterministic — Watts–Strogatz small-world plus deterministic cross-modal bridges, with no learned weights, no gradient-tuned objectives, no learned edge selection. The “Neural” in Neural Shortcut Network refers only to its role as a neural-embedding index. Phase 5’s guarantee is correspondingly modest: it guarantees structural reachability — by construction, every node has at least one edge to every other modality, so a 1-hop BFS sees all modalities — and makes no claim that the reached neighbors are semantically relevant. Whether the BFS-discovered cross-modal memory is the right one depends on the quality of the shared embedding space, not on the graph topology.
The graph store also carries a sixth component beyond the five edge-construction phases: an episode_csr member list that drives the episode-scoped fast path. It is a per-episode index (uint32 offsets into the embedding array), built once at corpus load time, queried by the RetrievalScope::EpisodeScoped contract.
What it’s not
MARS is not a vector database. Same conceptual layer — indexing, similarity, retrieval — but different latency envelope, different durability model, different deployment target. Think cuBLAS vs LAPACK: same operations, different hardware. The working set is seconds to hours of recent sensor data, bounded to fit in GPU VRAM.
This is also soft real-time, not hard real-time. The evaluation shows empirical p99 compliance with zero deadline misses over 30-second runs. True hard real-time (ISO-26262 ASIL-D) would require provable worst-case bounds, which MARS does not provide.
One known issue. The CUDA Graph capture path (--use-cuda-graph) currently corrupts results because counters and the episode-scoped reset are not re-initialised between graph replays — captured-graph replays return hit@15=0.004 and the next direct launch hits memory_cuda.cu:1197 — invalid argument. Tracked in docs/ARCHITECTURE.md §7.4 and in the paper’s Future Work section. The hand-fused FP16 path and episode-scoped fast path land cleanly without --use-cuda-graph.
Try it
git clone https://github.com/antonellof/MARS.git
cd MARS
make tests # host-only unit tests (17/17, no GPU needed)
make && make check # full build + hardware validation
make demo-av # 60 Hz AV perception demo
# Episode-scoped fast path on the kids-ball corpus
./demos/embodied_scene/demo --scope=episode
# Reproduce the head-to-head competitor benchmarks
pip install --extra-index-url=https://pypi.nvidia.com \
'cuvs-cu12==26.4.*' faiss-gpu-cu12 cupy-cuda12x
python3 scripts/bench_kids_ball_faiss.py \
--corpus results/competitors_20260417/corpus/kids_1m.bin
python3 scripts/bench_kids_ball_cuvs_cagra.py \
--corpus results/competitors_20260417/corpus/kids_1m.bin
The code is MIT licensed. The paper has the full methodology, kernel pseudocode, ablation studies, the §7.11 (episode-scoped retrieval) and §7.12 (head-to-head against FAISS / cuVS CAGRA) sections, the statistical caveats subsection (§7.2), and the §10.1 evaluation hardening track.
I’m particularly interested in feedback from anyone building real-time perception pipelines. The hypothesis — that an embodied loop’s existing notion of track / room / session / sub-task id is worth pushing all the way down into a GPU kernel parameter — needs validation from people who’ve actually shipped those loops. The data on the kids-ball corpus is dramatic, but I’d much rather know that someone with a real CLIP/CLAP corpus tried it and either confirmed the win or measured a counter-example.
Links:
- Paper (PDF, 1.97 MB)
- GitHub repository
- README — top-level overview
- Architecture deep dive — episode-scoped, head-to-head, FP16, known issues
- Benchmark results
- Head-to-head competitor SUMMARY — full FAISS / cuVS CAGRA / MARS run logs
- Next steps — Evaluation Hardening track ($15, ~2 days)
- Figure-generation script — re-renders the paper figures from the JSON artefacts